Dynamic Analysis of C++ Library Calls for Reverse Engineering
Practical guide to intercepting C++ library functions using dynamic analysis techniques + some benchmarking adventures

You’re looking at an HMI binary. Qt, stripped, a login screen that calls QString::compare on a password. strings shows nothing interesting. You open it in Ghidra and get this:
 Control flow explosion. Good luck doing this statically.
Control flow explosion. Good luck doing this statically.
The binary was compiled with something like Mystic-xorstr: compile-time string encryption backed by SIMD and fake branches. Painful to reverse statically. Or you can run ltrace:
1
2
3
4
5
6
$ ltrace -s 100 ./hmi
strlen("WrongPassword") = 13
_ZN7QString16fromAscii_helperEPKci(...) = 0x55fd4cc704d0
_Znwm(31, 31, 0, 31) = 0x55fd4cc70510
memcpy(0x55fd4cc70510, "MySecretPasswor", 15) = 0x55fd4cc70510
_ZNK7QString7compareERKS_N2Qt15CaseSensitivityE(...) = 0xfffffff6
Look at line 4. The compiler spat the plaintext through a c_str() temporary on the way into QString, and memcpy handed it to you in cleartext. All the obfuscation for nothing.

When ltrace Doesn’t Cut It
ltrace is wonderful when the string crosses a libc boundary. It’s useless when:
- The bytes never leave the Qt heap (a pure
QStringnever hitsmemcpy). - You want to log every compare, not just the password check.
- You need the return value, not just the arguments.
- You care about latency.
ltraceis slow and adds ptrace overhead.
At that point you need to hook the C++ method itself. For us that’s QString::compare. Name mangling, object layout, and symbol visibility become problems you actually have to solve, and the method you pick matters a lot if you care about performance.
The Target: QString::compare
1
2
// int QString::compare(const QString &other, Qt::CaseSensitivity cs) const;
// mangled: _ZNK7QString7compareERKS_N2Qt15CaseSensitivityE
Mangling: _ZNK marks a const member, 7QString and 7compare are length-prefixed names, ERKS_ is the const QString& parameter (S_ is a substitution back-ref), and N2Qt15CaseSensitivityE is the case-sensitivity enum. On x86-64 System V the call lands with $rdi = this, $rsi = second QString, $rdx = the enum.
For the hands-on I’ll use a toy where the secret only materializes inside Qt (a volatile loop defeats constant folding, so the bytes never hit .rodata or pass through memcpy):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
template<int K>
struct O{
static QString g(){
uint8_t d[]={K^77,K^121,K^83,K^101,K^99,K^114,K^101,K^116,
K^80,K^97,K^115,K^115,K^119,K^111,K^114,K^100};
QString r;
for(int i=0;i<16;++i){
volatile uint8_t x=d[i];
r+=QChar(x^K);
}
return r;
}
};
int main(){
QString i="WrongPassword";
auto s=O<0xA5>::g();
if(s.compare(i)==0) std::cout<<"Access Granted!"<<std::endl;
else std::cout<<"Access Denied!"<<std::endl;
return 0;
}
ltrace is useless on this one. Time to hook compare directly.
Four Ways to Hook It
| Method | Overhead per call | Memory | Runtime changes? | Best for |
|---|---|---|---|---|
| LD_PRELOAD | ~0.001 μs | +132 KB | No | hot paths, production targets |
| Library proxying | ~0.001 μs | +132 KB | No | replacing libraries wholesale |
| Frida | ~2.7 μs | +30 MB | Yes | iteration, exploration |
| GDB | interactive | n/a | Yes | one-off inspection |
Method 1: LD_PRELOAD
Replace the function at load time and you get native speed with a tiny memory footprint. We borrow Qt’s qPrintable macro for readable strings by compiling the interceptor against Qt:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
#include <dlfcn.h>
#include <cstdio>
#include <QString>
extern "C" {
int _ZNK7QString7compareERKS_N2Qt15CaseSensitivityE(void* this_ptr, void* other, int cs) {
static auto original = (int(*)(void*, void*, int))
dlsym(RTLD_NEXT, "_ZNK7QString7compareERKS_N2Qt15CaseSensitivityE");
int result = original(this_ptr, other, cs);
QString* str1 = (QString*)this_ptr;
QString* str2 = (QString*)other;
fprintf(stderr, "[COMPARE] \"%s\" == \"%s\" ? %s\n",
qPrintable(*str1),
qPrintable(*str2),
result == 0 ? "YES" : "NO");
return result;
}
}
1
2
3
LD_PRELOAD=./interceptor.so ./test
[COMPARE] "MySecretPassword" == "WrongPassword" ? NO
Access Denied!
Method 2: Library Proxying
A linker script can build a wrapper library that exports our hook and forwards every other symbol to the original library. This is handy when LD_PRELOAD isn’t enough, for instance when you want to override several symbols at once or change how the library loads.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# compile our interceptor
g++ -c -fPIC interceptor.cpp -o interceptor.o -ldl `pkg-config --cflags Qt5Core`
# linker script: our code + the real Qt lib
echo "GROUP ( interceptor.o /usr/lib/libQt5Core.so.5 )" > proxy.lds
g++ -shared -Wl,-T,proxy.lds -o libinterceptor.so
# option 1: patch the target to load our wrapper
patchelf --add-needed ./libinterceptor.so test
ldd test | head -5
linux-vdso.so.1 (0x00007fd466351000)
./libinterceptor.so (0x00007fd466343000)
libQt5Core.so.5 => /usr/lib/libQt5Core.so.5 (0x00007fd465c00000)
...
./test
[COMPARE] "MySecretPassword" == "WrongPassword" ? NO
Verify our hook took precedence:
1
2
nm -D libinterceptor.so | grep " T "
00000000000000c9 T _ZNK7QString7compareERKS_N2Qt15CaseSensitivityE
Replacing the system library wholesale (rather than patching the binary) gets painful fast. Qt uses symbol versioning and TLS, and the dynamic linker is strict about both:
1
2
3
4
sudo mv /usr/lib/libQt5Core.so.5 /usr/lib/libQt5Core.so.5.orig
sudo cp libinterceptor.so /usr/lib/libQt5Core.so.5
./test
./test: symbol lookup error: /usr/lib/libQt5Core.so.5: undefined symbol: qt_version_tag, version Qt_5.15
TLS (.tbss + R_X86_64_DTPMOD64 relocations in libQt5Core) is the other footgun: the dynamic linker has to allocate per-thread TLS blocks with the exact original layout, or you segfault on the first __tls_get_addr. Stick with the patchelf approach unless you really need to swap the lib globally.
Method 3: Frida
Frida is the right tool when you want to change hooks without recompiling. The annoying part with C++ is that most of what you’d want to call (qPrintable, toStdString) is a macro or template, not a callable export. You work around it by finding a real exported function. QString::utf16() returns a raw pointer to the UTF-16 data:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
const QT_LIB_NAME = "libQt5Core.so.5.15.17";
const qt5core = Process.findModuleByName(QT_LIB_NAME);
const utf16 = new NativeFunction(
qt5core.findExportByName("_ZNK7QString5utf16Ev"),
'pointer',
['pointer']
);
function qPrintable(qstring) {
return utf16(qstring).readUtf16String();
}
Interceptor.attach(qt5core.findExportByName("_ZNK7QString7compareERKS_N2Qt15CaseSensitivityE"), {
onEnter: function(args) {
console.log(`[compare] "${qPrintable(args[0])}" vs "${qPrintable(args[1])}"`);
},
onLeave: function(retval) {
console.log(`[compare] result: ${retval.toInt32()}`);
}
});
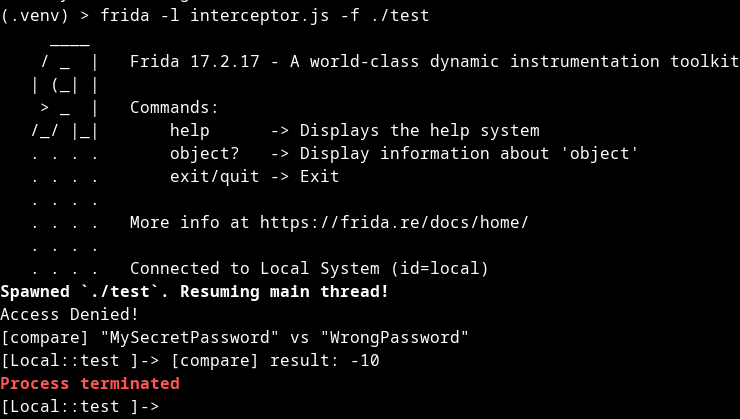 Frida successfully extracting both QString arguments at runtime despite obfuscation
Frida successfully extracting both QString arguments at runtime despite obfuscation
Two things to know. Frida needs the exact library name including version (libQt5Core.so.5.15.17, not libQt5Core.so.5). And you’ll end up chaining NativeFunction wrappers to poke at C++ objects, because Frida has no opinion on layout.
Method 4: GDB (for exploration)
Not really interception, just inspection. But it’s often the first thing you reach for when you don’t yet know what to hook.
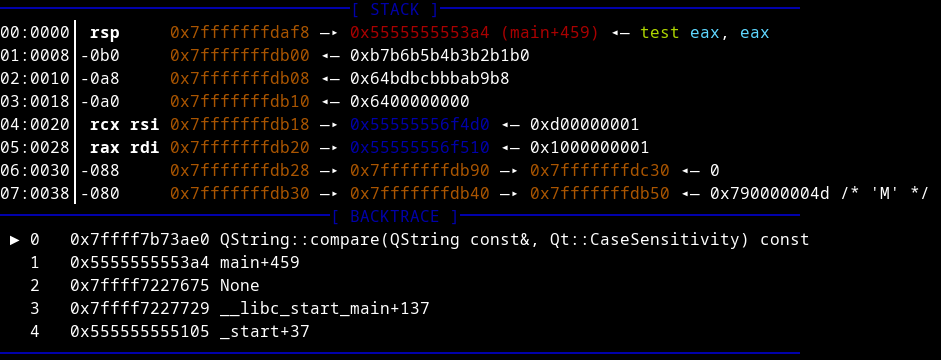 Breakpoint on QString::compare with arguments in registers
Breakpoint on QString::compare with arguments in registers
With the ABI mapping ($rdi / $rsi / $rdx), you can pull strings directly if you have the Qt headers loaded:
# Access QString's internal UTF-16 data
x/s ((QString*)$rdi)->d->data()
# Or examine the raw memory structure
x/10xg $rdi
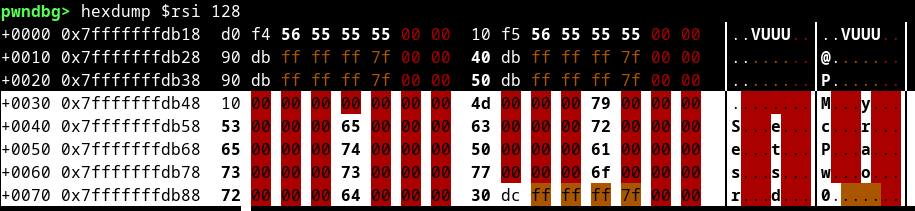 Extracting QString internal data with x/s
Extracting QString internal data with x/s
Use it to answer one question. Don’t use it to log every comparison across a 20-minute workload.
Performance: What Each Costs
Everyone says LD_PRELOAD is fast and Frida is flexible. What those datasheets don’t tell you is whether a given hook is cheap enough to leave running against ten million calls. So I wrote a benchmark.
Numbers below were collected against Frida 17.2.17 on x86_64. Newer Frida releases shift absolute numbers; the relative ordering has been stable.
Questions the benchmark was designed to answer:
- What’s the overhead on a hot path (millions of calls)?
- Which Frida runtime is better, V8 or QuickJS?
- How much does Frida’s CModule (C compiled to ASM via TinyCC, inlined into the trampoline) actually buy you?
- What’s the memory cost?
 It was not 20 minutes
It was not 20 minutes
1
2
3
4
5
6
7
Hot Path Analysis (1M calls, baseline: 3112 μs):
--------------------------------------------------
LD_PRELOAD : + 1035 μs (+ 33.3%) = 0.001 μs/call
Frida onEnter (V8) : +2772722 μs (+89097.8%) = 2.773 μs/call
Frida onLeave (V8) : +1710558 μs (+54966.5%) = 1.711 μs/call
Frida Both (V8) : +2734145 μs (+87858.1%) = 2.734 μs/call
Frida CModule : + 286732 μs (+ 9213.8%) = 0.287 μs/call
1
2
3
4
5
6
7
8
Memory Usage Analysis:
--------------------------------------------------
Baseline: 2140 KB
LD_PRELOAD : 2272 KB (+ 132 KB, + 6.2%)
Frida onEnter (V8) : 31880 KB (+ 29740 KB, +1389.7%)
Frida onLeave (V8) : 31940 KB (+ 29800 KB, +1392.5%)
Frida Both (V8) : 31894 KB (+ 29754 KB, +1390.4%)
Frida CModule : 31878 KB (+ 29738 KB, +1389.6%)
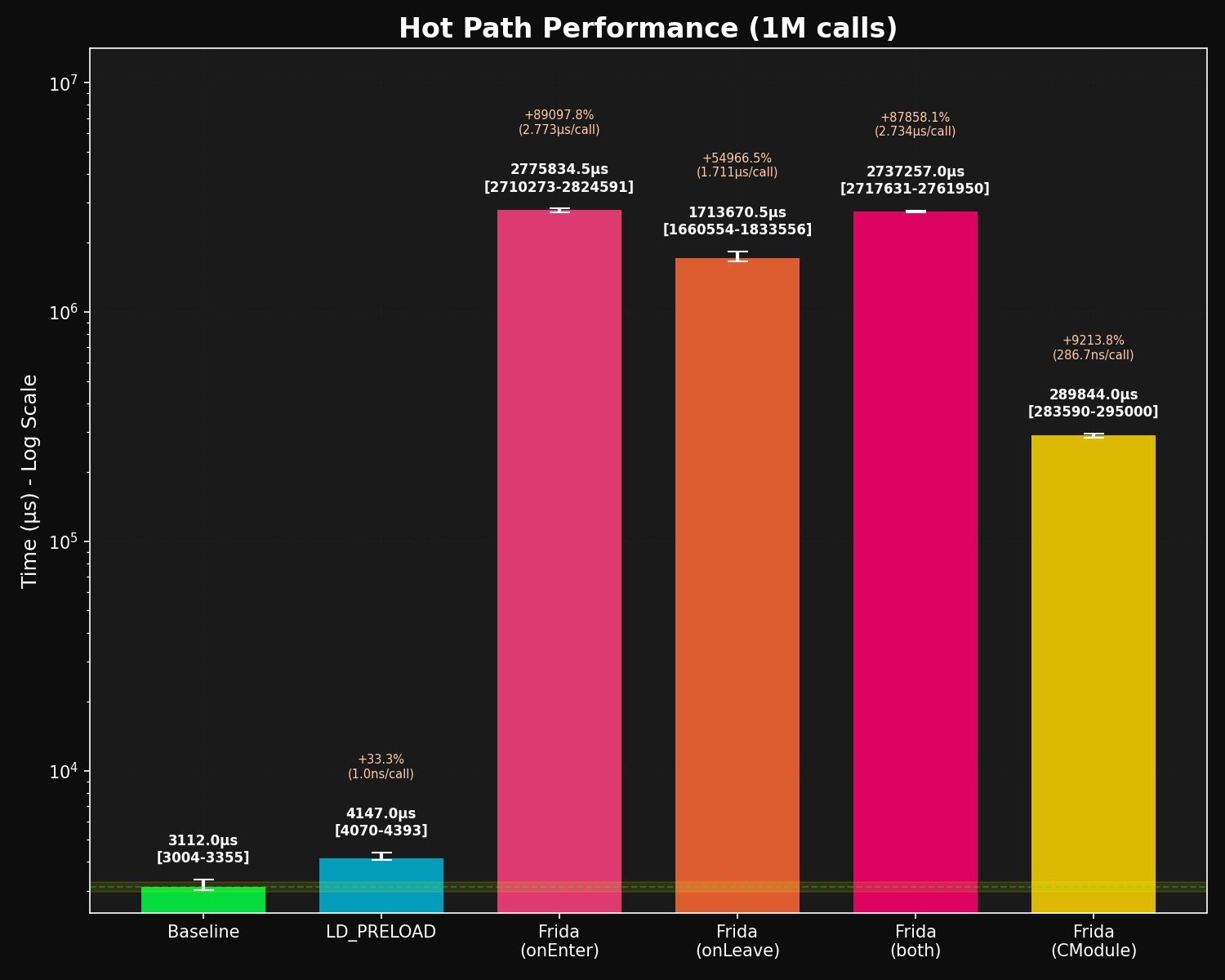 Hot path performance - LD_PRELOAD sits at the bottom
Hot path performance - LD_PRELOAD sits at the bottom
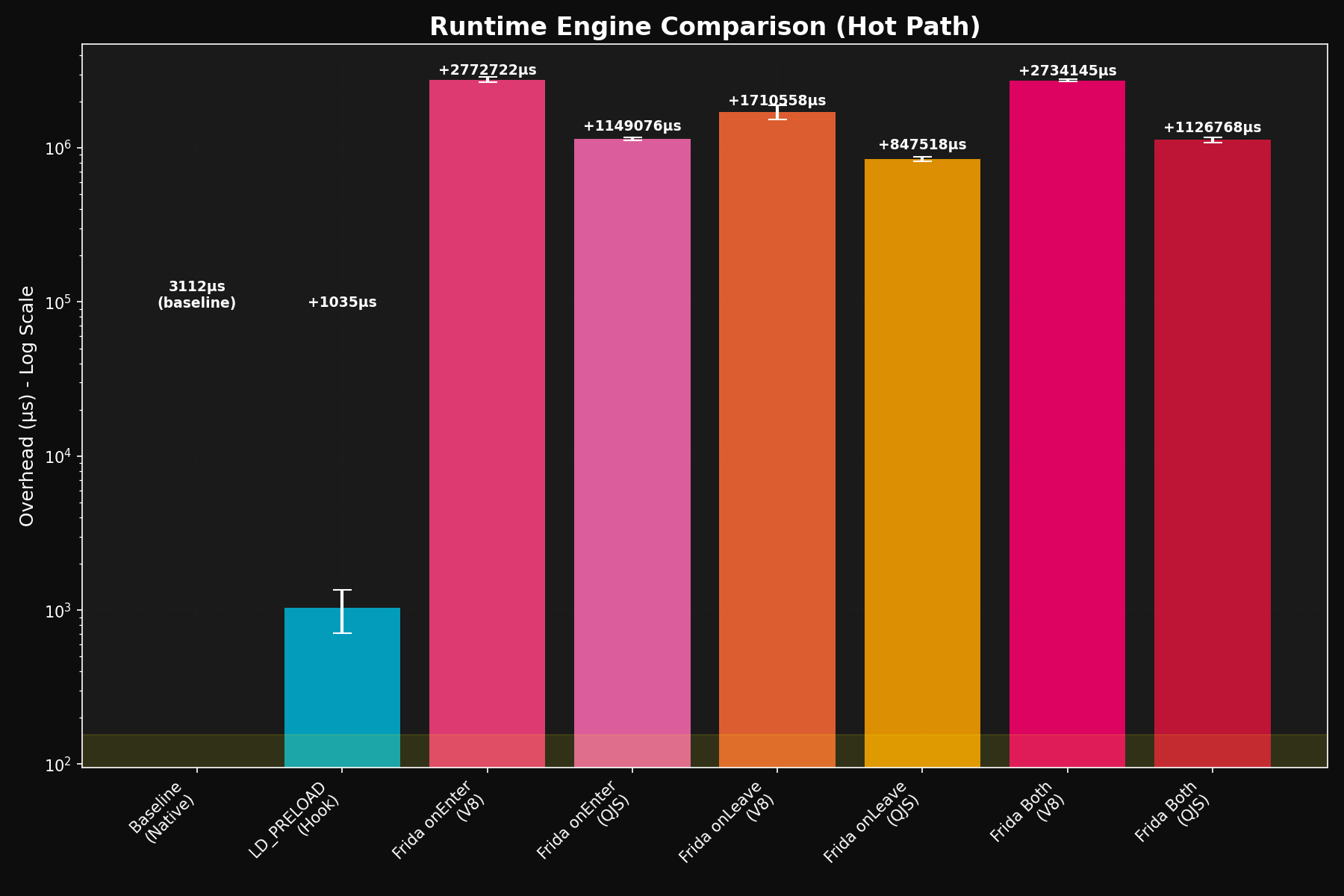 V8 vs QuickJS
V8 vs QuickJS
Benchmark source: github.com/f0rw4rd/cpp-interception-benchmarks. Adapt it for your own workloads.
LD_PRELOAD is ~2700× faster than a Frida JS hook (0.001 μs/call vs 2.773 μs/call). In a tight loop that turns a hook from invisible into a process that never finishes. One thing that surprised me while writing this: splitting into onEnter-only to save time doesn’t help. Frida Both (2.734 μs) costs about the same as onEnter alone, so the combined path is already optimized.
Frida’s two runtimes trade off differently. V8 has higher baseline overhead but JIT and better complex-operation handling; QuickJS starts faster and uses less memory but slows down as your hook does more work.
CModules help, but not enough to use them everywhere. 0.287 μs/call, roughly 10× faster than JS and still 287× slower than LD_PRELOAD. Reach for them when you need Frida’s runtime flexibility on a hot path.
Memory is where Frida really hurts on embedded targets. LD_PRELOAD adds ~132 KB. Frida starts at ~30 MB baseline for the JS engine and agent infrastructure, and grows from there. That’s a showstopper on a 64 MB HMI; on an analyst’s workstation it doesn’t matter.
Why C++ Is Harder Than C
QString::compare is an easy target: non-inlined, GLOBAL-bound, non-virtual, and exported by libQt5Core. Plenty of C++ code doesn’t give you all four.
Name Mangling
C++ compilers encode class hierarchies, namespaces, and function signatures into symbol names. QString::toUtf8() becomes _ZNK7QString6toUtf8Ev under GCC/Clang’s Itanium ABI. MSVC uses a different scheme (?toUtf8@QString@@QEBA?AVQByteArray@@XZ). Templates get bad fast:
1
2
_ZNSt6vectorISt10shared_ptrI6WidgetESaIS2_EE9push_backERKS2_
// std::vector<std::shared_ptr<Widget>>::push_back()
Pipe through c++filt for readability; use the mangled form when you link or dlsym.
Symbol Visibility
Not every symbol is interceptable. readelf -Ws shows what you’ve got to work with:
1
2
3
readelf -Ws libQt5Core.so | grep QString
# Num Addr Size Type Bind Vis Ndx Name
1287: ... FUNC GLOBAL DEFAULT 12 _ZN7QString6appendERKS_@@Qt_5
GLOBAL/WEAK binding with DEFAULT visibility means you can hook it by name. LOCAL, HIDDEN, or PROTECTED means you can’t (not via name, at least). The @@Qt_5 suffix is symbol versioning: use the full suffixed name with dlsym or you’ll bind to the wrong ABI.
What that means in practice:
- Hook by name (LD_PRELOAD, library proxy, Frida-by-name, PTRACE, eBPF uprobes): virtual functions (via
_ZTV*), instantiated templates, operators, constructors/destructors — anything exported. - Hook by address only (Frida-by-address, PTRACE, eBPF uprobes at a specific offset): inline functions, lambdas, static functions, uninstantiated templates.
- Can’t hook: template definitions that were never instantiated — there’s no code to hook.
vtables, Inheritance, Template Explosion
Virtual calls go through a vtable. Static analysis sees call [eax+0x8] and can’t resolve the target; at runtime it’s concrete and hookable via the _ZTV* symbol. Multiple inheritance is worse: each base subobject may need a this-pointer adjustment thunk (sub ecx, 8; jmp real_function) before the real method. Hook the unadjusted entry and your this pointer is off.
Templates produce a unique symbol per instantiation:
1
2
_ZNSt6vectorIiSaIiEE9push_backERKi // vector<int>::push_back
_ZNSt6vectorIfSaIfEE9push_backERKf // vector<float>::push_back
So “hook vector::push_back” isn’t a thing. Hook the specific instantiation used in the target.
Constructors get three symbols (C1 complete, C2 base, sometimes C3), destructors also three (D0 deleting, D1 complete, D2 base). Usually you only need C1/D1.
Compiler optimization eats the rest. Inlining hides a function inside its caller. Devirtualization turns virtual calls into direct ones when the type is known. LTO merges or strips identical code. If a function you expect isn’t in the symbol table, optimization probably got it.
Finding the Right Symbol
1
2
3
4
ldd application | grep -i qt # find the library
nm -D libQt5Core.so | c++filt | grep Compare # readable listing, grep for what you want
nm -D libQt5Core.so | grep "7compare" # exact mangled name
readelf -Ws libQt5Core.so | grep _ZNK7QString # visibility + symbol version